Uno dei software più interessanti che ho visto negli ultimi tempi è, sicuramente, Teiid di JBoss, una comunità nata, e sostenuta da Red Hat, specializzata nella creazione e nel supporto di progetti open-source di tipo middleware. Il suo nome è quello di una varietà di lucertole, ma solo perché questo nome ha la particolarità di includere le lettere “EII”, che sono l’acronimo di Enterprise Information Integration (Integrazione di informazioni aziendali).

Che cos’è, a cosa serve. perché è così interessante un software come Teiid?
I sistemi EII consentono alle applicazioni un accesso ai dati virtualizzato, un approccio logico che astrae dalla natura fisica dei dati, in particolare fornendo un accesso uniforme ad un unico insieme di strutture, rappresentate con denominazioni uniformi, il cui scopo principale è di consentire, agli utenti o ai programmi, l’accesso ad un ampio numero di sorgenti dati eterogenee facendole apparire loro come una singola sorgente dati omogenea.
L’obiettivo è quindi quello di semplificare, agli utenti o a i programmatori, l’utilizzo di molte sorgenti dati di tipo diverso, rendendole accessibili in modo unificato e mediante le metodologie più semplici ed utili e, sopratutto, in modo completamente trasparente, consentendo quindi la semplificazione, standardizzazione ed astrazione dell’accesso ai dati.
Teiid raggiunge in pieno questo obiettivo, e consente di utilizzare i propri dati in modo estremamente versatile e potente, come testimonia il motto che lo accompagna che corrisponde, traducendolo, alla promessa: “i dati che vuoi dai dati che hai”.
In pratica, è un sistema che si pone fra i dati a disposizione e i programmi che devono interrogarli e manipolarli, e rende possibile:
- l’accesso ai dati mediante una sola connessione, anche quando in realtà provengono da sorgenti separate e di tipo diverso,
- la trasformazione dei dati, in tempo reale, in modo da presentarli ai progammi in modo diverso da come sono strutturati, come appartenenti a strutture che in realtà non esistono fisicamente
- l’accesso ai dati, da parte dei programmi, mediante diverse tipologie di connessione, anche quando le sorgenti originali dei dati non le prevedono
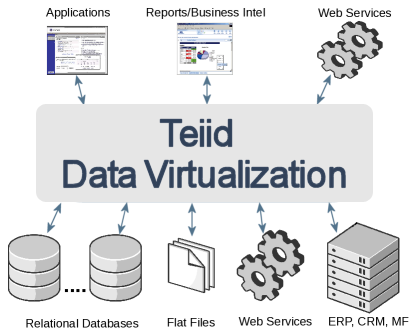
Teiid serve per realizzare ed interrogare particolari strutture chiamate “database virtuali” (o VDB), che non contengono dati bensì metadati, quali informazioni sui dati e la loro collocazione fisica. Attraverso i VBD i programmi hanno accesso ai dati di una o più sorgenti diverse, anche di tipo etereogeneo, contemporaneamente ed in tempo reale.
Teiid è costituito sostanzialmente da un motore per query distribuite di tipo relazionale SQL, procedurale, XML o XQuery, i cui risultati appaiono agli utenti “consolidati” e relativi ad una singola sorgente anche se in realtà corrispondenti a sorgenti diverse.
Tra le caratteristiche principali della attuale versione stabile, la 8.2:
- l’accesso ai dati necessita di una singola connessione
- avviene verso un database composito “virtuale”, VDB
- il VDB può comporre sorgenti di moltissimi tipi: JDBC, testo delimitato, web services, ldap, salesforce, google spreadsheet, ecc.
- il VDB può essere interrogato mediante client JDBC (driver teiid), ODBC (driver postgresql) o SOAP (web services)
- è possibile utilizzare una singola query, con una sintassi uniforme ed indipendente dal tipo di sorgenti
- permette l’accesso mediante SQL anche per sorgenti che non lo supportano
- le prestazioni vengono ottimizzate mediante algoritmi dinamici di join e capacità native delle sorgenti
- il client può utilizzare prepared statement, stored procedures e funzioni, anche definite dall’utente
- il client può utilizzare transazioni e aggiornamenti distribuiti
- il sistema dspone di log completi delle interrogazioni e dei comandi processati
- il sistema supporta meccanismi di caching di vario tipo e viste materializzate
Inoltre:
- dispone di architettura aperta e connettività estensibili per supportare sorgenti di tipo diverso, che chiunque può creare ed aggiungere al sistema, autonomamente.
- dispone nativamente dei traduttori per sorgenti: oracle, ldap, jpa2, intersystems-cache, postgresql, informix, teiid, map-cache, jdbc-simple, sqlserver, salesforce, teradata, olap, file, loopback, access, ws, ingres93, netezza, mysql5, ingres, metamatrix, h2, jdbc-ansi, db2, google-spreadsheet, infinispan-cache, hive, modeshape, derby, sybase, hsql, mysql
- supporta gli standard sql, jdbc, odbc, xa, uml, emf, mof, xmi, xml, xml schema, xlst, xpath, xquery, soap, wsdl, uddi, ws-i, j2ee, eclipse, ssl, http
- consente sia la creazione manuale di VBD “semplificati”, in XML, che la creazione di VDB “complessi” mediante un software separato, Teiid Designer, basato sull’IDE Eclipse
- è un progetto molto consolidato (deriva da un prodotto un tempo commerciale)
- è un progetto molto ben documentato
- E’ un progetto molto prolifico (oltre 6 release nell’ultimo anno)
- la licenza è di tipo LGPL
Tempo permettendo, mi piacerebbe approfondire questi argomenti e le mie esperienze con Teiid, in qualche prossimo articolo.